Database keys
Database tables are an implementation of relations. Relations are defined to be sets of tuples and as such have all the properties of sets. Unfortunately SQL tables are not natively sets unless uniqueness constraints are placed on them. This article continues a discussion of uniqueness constraints, specifically it formalizes the notion of super key, primary key, and candidate key.
Review of super key and primary key
Let’s look again at the relation scheme diagram for Customers and Orders.

Remember that a super key is any set of attributes whose values, taken together, uniquely identify each row of a table—and that a primary key is the specific super key set of attributes that we picked to serve as the unique identifier for rows of this table. We are showing the PK attributes in the scheme diagram for convenience, understanding that keys are a constraint on the table (relation). In fact, not every super key can be selected to be a primary key; those that can be selected are known as candidate keys.
Candidate keys
Before picking the PK, we need to identify any candidate key that we can find for a table. A CK is a minimal super key; “minimal” means that if you take away any one attribute from the set, it is no longer a super key. Given a CK, if you add one attribute to the set, it is no longer minimal (but it’s still a super key). Since in a PK we don’t want any more attributes than are necessary, these “minimal” super keys are the ones we choose from. The word “candidate” simply means that this set of attributes (minimal super key) could be used as the primary key. It is possible for a relation scheme to have several CK’s of different lengths.
Whether a set of attributes constitutes a CK or not depends
entirely on the data in the table—not just on whatever data happens to be in
the table at the moment, but on any set of data that could realistically be in this table
over the life of the database.
Consider the Customers PK {first_name, last_name, phone}. Can it uniquely
identify anyone we would want as a customer? It does, but
only if we make some assumptions. Below are some key observations about this set
of attributes.Example: Customers PK
Every table must have at least one candidate key; if you can’t find one, your design is flawed or unfinished. Former heavyweight boxing champion George Foreman is said to have named every one of his sons “George Foreman.” If they were all customers of ours, living at the same address with the same phone number, we would need at least one more descriptive attribute—probably the birth date—to distinguish between them.
PK size might matter
You’re probably thinking that it’s a real nuisance and waste of space to copy all three of the Customer PK attributes to establish the FK in Orders. If so, you’re right. Imagine one customer placing just ten orders, their name and phone number is in the database eleven times: once in the Customers table and once for each of the ten orders placed in the Orders table. Remember that we purposely designed the Customers table without considering its association with Orders. Now that it’s the parent in a one-to-many association, we have to ask if the PK is small enough to be copied into the child table. In some tables, it will be—so we’re done; in other tables, like Customers, it isn’t—to resolve this we’ll have to make up a PK that is small enough. There are two types of “made up” primary keys:
- A surrogate PK is a single, small attribute (such as a number) that has no descriptive value—it doesn’t tell us anything about the real-world individual. Most ID numbers you may have encountered fit this description. Surrogate keys are created for the convenience of the database designer only. They are often a nuisance for database users, and should normally be hidden from the user by the interface of an application that communicates with a database system.
- A substitute PK is a single, small attribute that has at least some descriptive value (such as an abbreviation). Examples of substitute keys include the two-letter postal codes for the states of the United States and the three-letter codes for worldwide airports. Substitute keys are also created for the convenience of the database designer. They are frequently still a nuisance for database users (E.g.: what is the code for the airport in Vancouver Canada?), although less so than surrogate PKs as most of these abbreviations are widely used and understood by people.
Do not automatically add “ID numbers” (surrogate keys) or substitute keys to a table until you are sure of the following:
- there is at least one candidate key (before the surrogate is added),
- the table is a parent in at least one association, and
- there is no candidate key small enough for its values to be copied many times into the child table.
These rules apply to surrogate and substitute keys that you (and your co-workers) add to your own tables. However, you might find that a class already has an attribute that appears to be a surrogate or substitute key, but has been defined by someone else—usually a standards-setting organization or a government agency. We call this attribute an external key. In the external organization’s database, there is a candidate key for it, whether or not you have access to it or include its value(s) in your own database. In these situations, you may use it as a descriptive attribute in both UML and thus also in the relation scheme diagram. Such attributes need to be well documented. Like other descriptive attributes, an external key might or might not become part of a candidate key in your database. We will encounter many of these (such as the zip code, UPC, and ISBN) in our examples.
There is one special case of an external key that requires careful handling in your database design: the United States social security number (SSN). Originally intended for use only to identify social security participants, it has now become so over-used as an identifier that access to it poses risks of serious damage to individuals, even including identity theft. Please do not ever use the SSN in your database unless you are required to do so by law (for example, to file tax information). Even then, do not use it as a primary key that would be viewable to everyone who can access your database. Similar care should be taken with other sensitive information such as state identification, credit card numbers, bank account numbers, etc.
Example: Revising the customers-orders relation scheme
All of what we have done here applies to the relation scheme and tables only—the UML class diagram doesn’t change (unless we have to add descriptive attributes). Remember, a UML class diagram never includes implementation details such as PK, CK, and FK information; all of these are artifacts of implementing the UML class diagram by mapping it to the relational model and thus must be specified in the relational database scheme diagram. Our revised scheme, with surrogate PK customer ID is given below.
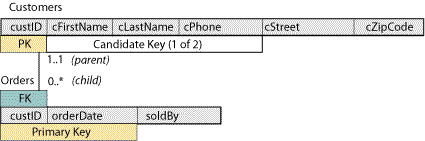
Note how the Customers table still defines a uniqueness constraint on the set of attributes {cFirstName, cLastName, cPhone}. This was a CK before introducing the surrogate PK and continues to be a CK after introducing the surrogate PK. If this constraint is missing, then, the relation scheme is incorrect.
In the Orders scheme, the custID FK still represents the PK attributes from Customers—it tells us which customer placed the order. In the child table, it can be used as if it were a naturally occurring attribute of the table and thus can be in a candidate key or primary key, as demonstrated here.
| 1234 | Tom | Jewett | 714-555-1212 | 10200 Slater | 92708 |
| 5678 | Alvaro | Monge | 562-333-4141 | 2145 Main | 90840 |
| 9012 | Wayne | Dick | 562-777-3030 | 1250 Bellflower | 90840 |
| 5678 | 2003-07-14 | Patrick |
| 9012 | 2003-07-14 | Patrick |
| 5678 | 2003-07-18 | Kathleen |
| 5678 | 2003-07-20 | Kathleen |
The Orders table now no longer has the name and phone number of the customer placing the order. Instead, we have an integer identifying the customer. That is clearly not as informative as our previous version of the Orders table, however, the advantage gained is that a customer’s personal information is in only one place rather than being repeated for as many orders as a customer has placed. In the section on joins we will learn to concatenate together (to join) information from two or more tables. That will provide us with the necessary skills to retrieve the orders and information (name, phone, address) about who placed the order as shown below.
| 5678 | Alvaro | Monge | 562-333-4141 | 2145 Main | 90840 | 2003-07-14 | Patrick |
| 9012 | Wayne | Dick | 562-777-3030 | 1250 Bellflower | 90840 | 2003-07-14 | Patrick |
| 5678 | Alvaro | Monge | 562-333-4141 | 2145 Main | 90840 | 2003-07-18 | Kathleen |
| 5678 | Alvaro | Monge | 562-333-4141 | 2145 Main | 90840 | 2003-07-20 | Kathleen |